





Click the image to view the GT annotations
Hengyu Liu1,*, Chenxin Li1,*, Zhengxin Li2, Yipeng Wu2, Wuyang Li3, Zhiqin Yang1, Zhenyuan Zhang4, Yunlong Lin5, Sirui Han4,†, Brandon Y. Feng6,†
1CUHK ![]() ,
2TJU
,
2TJU ![]() ,
3EPFL
,
3EPFL ![]() ,
4HKUST
,
4HKUST ![]() ,
5XMU
,
5XMU ![]() ,
6MIT
,
6MIT ![]()
🌟NeurIPS DB 2025🌟
We propose IR3D-Bench, a benchmark that challenges VLMs to demonstrate real scene understanding by actively recreating 3D structures from images using tools. An "understanding-by-creating" approach that probes the generative and tool-using capacity of vision-language agents (VLAs), moving beyond the descriptive or conversational capacity measured by traditional scene understanding benchmarks.
![]() Click to jump to each section.
Click to jump to each section.
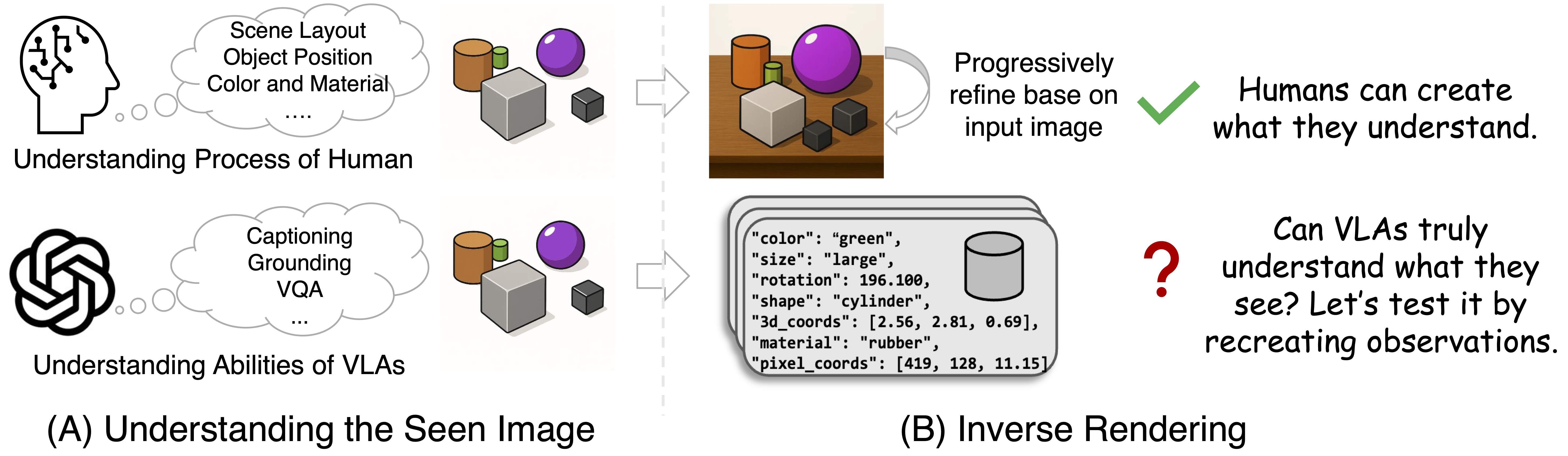
Humans demonstrate true understanding through creation and recreate observed scenes because we genuinely comprehend spatial relationships and physical attributes. In contrast, current Vision-Language Agents (VLAs) are primarily evaluated on recognition tasks like captioning or QA, which fail to assess deeper understanding. Can VLAs truly understand what they see ? IR3D-Bench test it by letting them recreating the observations.
We use the CLEVR dataset, a popular benchmark for 3D vision tasks. Our work uses the validation split, which includes 15,000 synthetic images. Each image contains 3 to 10 objects with detailed annotations covering their 3D coordinates, pixel-space projections, shape, color, size, material, and spatial relationships. These rich annotations make CLEVR ideal for evaluating 3D reconstruction and spatial reasoning in a controlled environment.
Click the image to view the GT annotations
VLM is prompted with an image and textual instruction to infer object-level geometric and material parameters, outputting structured scene representations in JSON format. These predictions are subsequently used to reconstruct the scene in Blender.
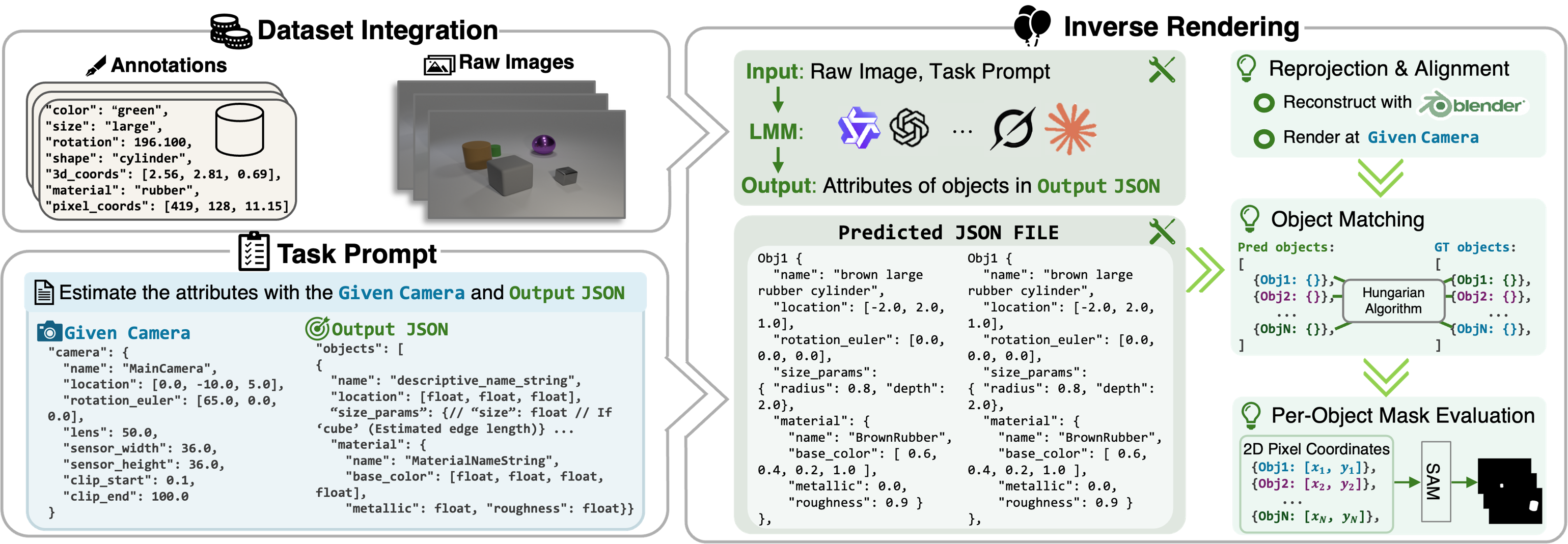
We provide a comprehensive view of the VLA's internal world model and generative precision:
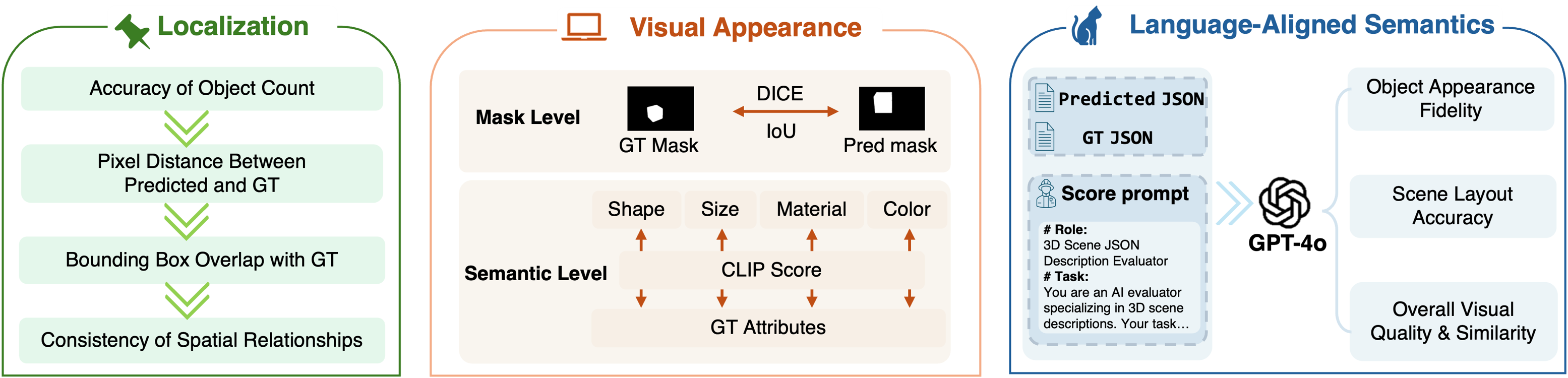
Gemini-2.5-pro demonstrates strong understanding of object spatial positions and relative layouts. Grok-3 excels at modeling fine-grained details such as material and color. Qwen2.5-VL-72B struggles in more complex scenarios.
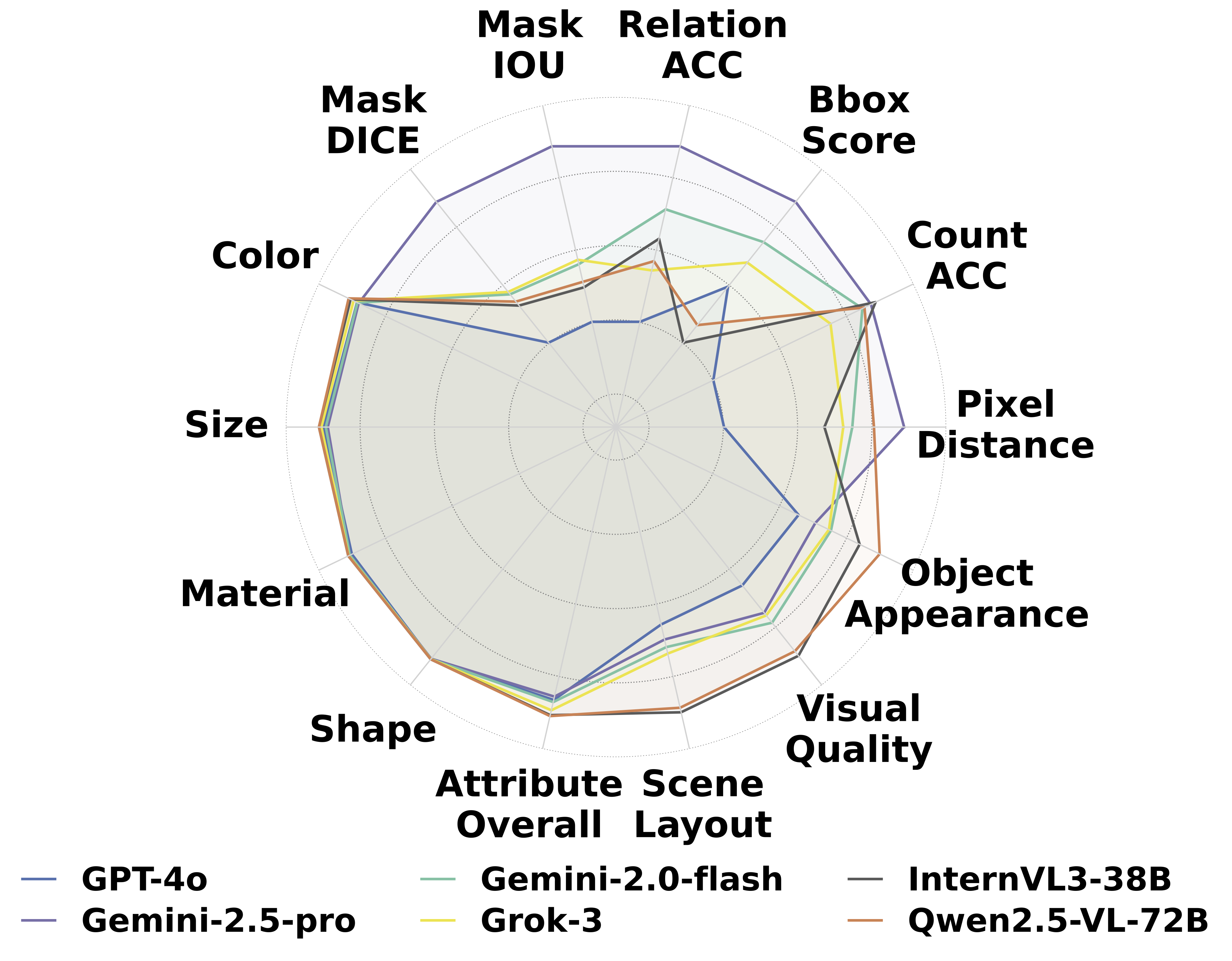
| Model | Release | Layout & Localization | Relation Instance Seg. | CLIP Score | LLM Score | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pix. Dist.↓ | Count Acc↑ | Bbox↑ | Rel. Acc↑ | IoU↑ | Dice↑ | Color↑ | Size↑ | Material↑ | Shape↑ | Overall↑ | Obj App.↑ | Layout↑ | Overall↑ | ||
| Latest Proprietary Models | |||||||||||||||
| Gemini-2.5-pro | 2025-03 | 0.3791 | 1.00 | 0.45 | 0.55 | 0.11 | 0.18 | 96.12 | 97.00 | 99.50 | 99.75 | 93.08 | 2.96 | 2.05 | 2.62 |
| Gemini-2.0-flash | 2025-02 | 0.4291 | 0.99 | 0.37 | 0.46 | 0.08 | 0.13 | 96.59 | 97.67 | 99.41 | 99.92 | 94.97 | 2.99 | 2.08 | 2.72 |
| Claude3.5-Sonnet | 2024-10 | 0.5402 | 0.87 | 0.50 | 0.28 | 0.09 | 0.14 | 93.19 | 96.77 | 97.39 | 98.60 | 91.39 | 2.67 | 1.85 | 2.28 |
| Claude-3.7-Sonnet | 2025-02 | 0.5099 | 0.93 | 0.53 | 0.38 | 0.09 | 0.14 | 97.71 | 98.34 | 99.42 | 99.09 | 96.36 | 3.05 | 2.10 | 2.82 |
| GPT-4.1 | 2025-04 | 0.4366 | 1.00 | 0.48 | 0.42 | 0.08 | 0.13 | 97.55 | 97.34 | 98.96 | 98.66 | 94.59 | 2.68 | 1.66 | 2.34 |
| GPT-4o | 2024-11 | 0.5528 | 0.94 | 0.29 | 0.30 | 0.07 | 0.11 | 96.70 | 98.36 | 98.66 | 99.88 | 94.22 | 2.90 | 1.94 | 2.52 |
| grok-3 | 2024-12 | 0.4378 | 0.98 | 0.33 | 0.38 | 0.08 | 0.13 | 98.04 | 99.15 | 99.87 | 99.89 | 97.80 | 3.02 | 2.06 | 2.71 |
| Open-source Models | |||||||||||||||
| DeepSeek-VL2 | 2024-12 | × Failed | |||||||||||||
| Llama-3.2-11B-Vision | 2024-09 | × Failed | |||||||||||||
| H2OVL-Mississippi-2B | 2024-10 | × Failed | |||||||||||||
| LLaVA-NeXT | 2025-01 | 0.6835 | 0.69 | 0.38 | 0.12 | 0.03 | 0.04 | 92.11 | 96.78 | 96.31 | 96.85 | 89.17 | 2.03 | 0.96 | 1.47 |
| Mistral3 | 2025-01 | 0.4733 | 0.99 | 0.26 | 0.44 | 0.06 | 0.11 | 99.56 | 99.79 | 99.85 | 99.90 | 97.95 | 3.17 | 2.16 | 2.78 |
| phi-3.5-Vision | 2024-07 | 0.6027 | 0.80 | 0.45 | 0.13 | 0.02 | 0.03 | 91.44 | 96.35 | 93.08 | 96.35 | 87.06 | 2.10 | 1.01 | 1.53 |
| phi4_mm | 2025-02 | 0.6192 | 0.92 | 0.21 | 0.32 | 0.03 | 0.05 | 94.82 | 93.16 | 96.02 | 99.58 | 92.63 | 2.59 | 1.49 | 2.04 |
| Pixtral-12B | 2024-11 | 0.4661 | 0.98 | 0.23 | 0.42 | 0.07 | 0.11 | 99.28 | 99.90 | 99.03 | 99.83 | 98.93 | 3.22 | 2.15 | 2.78 |
| Aria | 2024-11 | 0.5932 | 0.87 | 0.25 | 0.17 | 0.05 | 0.08 | 95.96 | 99.22 | 99.22 | 99.80 | 92.09 | 2.90 | 1.91 | 2.44 |
| Idefics3-8B | 2024-08 | 0.9100 | 0.97 | 0.11 | 0.18 | 0.03 | 0.06 | 98.35 | 99.83 | 95.35 | 99.98 | 97.97 | 3.14 | 1.79 | 2.48 |
| InternVL2.5-8B | 2024-11 | 0.9511 | 1.00 | 0.22 | 0.28 | 0.03 | 0.05 | 99.85 | 99.92 | 99.85 | 99.98 | 99.80 | 3.02 | 1.86 | 2.51 |
| InternVL2.5-38B | 2024-11 | 0.5233 | 1.00 | 0.23 | 0.38 | 0.07 | 0.11 | 99.79 | 99.98 | 100.00 | 100.00 | 99.86 | 3.26 | 2.17 | 2.83 |
| InternVL3-8B | 2025-04 | 0.5549 | 1.00 | 0.32 | 0.30 | 0.05 | 0.08 | 99.20 | 99.49 | 98.82 | 99.62 | 98.82 | 3.00 | 1.89 | 2.49 |
| InternVL3-38B | 2025-04 | 0.4560 | 1.00 | 0.18 | 0.40 | 0.07 | 0.13 | 99.15 | 99.98 | 100.00 | 100.00 | 99.47 | 3.25 | 2.22 | 2.89 |
| Qwen2.5-VL-7B | 2025-01 | 0.6537 | 0.96 | 0.40 | 0.30 | 0.04 | 0.06 | 98.21 | 99.60 | 99.71 | 99.86 | 96.89 | 3.04 | 1.95 | 2.55 |
| Qwen2.5-VL-72B | 2025-01 | 0.4082 | 1.00 | 0.21 | 0.39 | 0.08 | 0.13 | 99.86 | 99.98 | 99.99 | 99.98 | 99.80 | 3.24 | 2.20 | 3.02 |



















As the number of refinements increases, the performance of cases that performed poorly on gpt-4o gradually improves, even outperforming Gemini-2.5-pro.




Obj1{
"name": "brown large rubber cylinder",
"location": [-2.0, 2.0, 1.0],
"rotation_euler": [0.0, 0.0, 0.0],
"size_params": { "radius": 0.8, "depth": 2.0},
"material": {
"name": "BrownRubber",
"base_color": [ 0.6, 0.4, 0.2, 1.0 ],
"metallic": 0.0,
"roughness": 0.9 }
}

IR3D-Bench redefines VLM scene understanding through agentic inverse rendering, challenging VLAs to reconstruct 3D scenes from 2D images via automatic tool-use. Our experiments find that current VLMs grasp high-level object attributes and tool-use abilities, but struggle with precise spatial control. We found that iterative refinement and careful prompt design can improve reconstruction quality, providing guidance for future VLM research. With IR3D-Bench, we provide the community with a systematic framework to measure progress of VLM scene understanding, moving beyond passive observation to agentic understanding-by-creating.
@article{liu2025ir3d,
title={IR3D-Bench: Evaluating Vision-Language Model Scene Understanding as Agentic Inverse Rendering},
author={Liu, Parker and Li, Chenxin and Li, Zhengxin and Wu, Yipeng, and Li, Wuyang and Yang, Zhiqin and Zhang, Zhenyuan and Lin, Yunlong and Han, Sirui and Feng, Brandon},
journal={arXiv preprint},
year={2025}
}
The website template was originally borrowed from here.